Memory Alignment and Performance
11 Jul 2017Introduction
Memory alignment is not a hot topic. Usually, we don’t worry about it and very few people will bother to know if the pointer returned by malloc is 16 or 64 bytes aligned. However, I suspect that memory alignment may affect the performance someway in x86-64 processors.
In this article I want to analyze if memory alignment has effects on performance.
Previous Work
Although this has been partially studied I’ll try to fill some gaps. On the one hand, Lemire D. covered the performance when iterating all the elements of an array. However, this case is not that interesting because if you load all the elements the number of cache misses at the end will be almost the same. On the other hand Gauthier L. covered a specific access pattern which showed better performance with aligned access.
However, this approaches didn’t considered the alignment of the memory allocated but the way data is accessed.
Therefore, I will focus on analyzing if the alignment of the memory allocated affects the performance when doing random access. I won’t force the unalignment; instead I will use memory allocators that only guarantee some level of alignment.
Random Access
Before continuing, I’ll explain why random access could have drawbacks.
Let’s suppose that cache lines have a size of 64 bytes. And you have an element of that size. Thus if the data is 64 bytes aligned the element will perfectly fit in a cache line.

However, if doesn’t fit in a cache line it will be stored between two lines. Therefore we will need to load two blocks of memory instead of one to use the element.

Furthermore, SIMD can’t work with very low memory alignment, so programs which rely on these instructions may be affected.
Experiment
For this analysis we will use the function aligned_alloc that appeared in C++11. This function allows us to choose how much memory alignment is required for the allocated memory.
To test the performance we will allocate arrays with different memory alignments of 1,000,000 elements and then we will load 1% of those elements.
The code used for the analysis can be found here.
Results
There are a few things that I have to point out before showing the results. The first is that there are big variations between test executions, so I can’t ensure as many things as I would like. Thus, I’m only going to show what I am sure about after many different approaches.
The first main result is that I haven’t seen serious differences while changing the size of the element that we want to load. Actually, using 2 or 4-byte alignment I’ve notice a small growth in execution time, while I haven’t notice differences using more restrictive memory alignment.
Finally, after comparing the execution time for different memory alignments using element sizes between 32 and 96 bytes I’ve obtained the following graph:
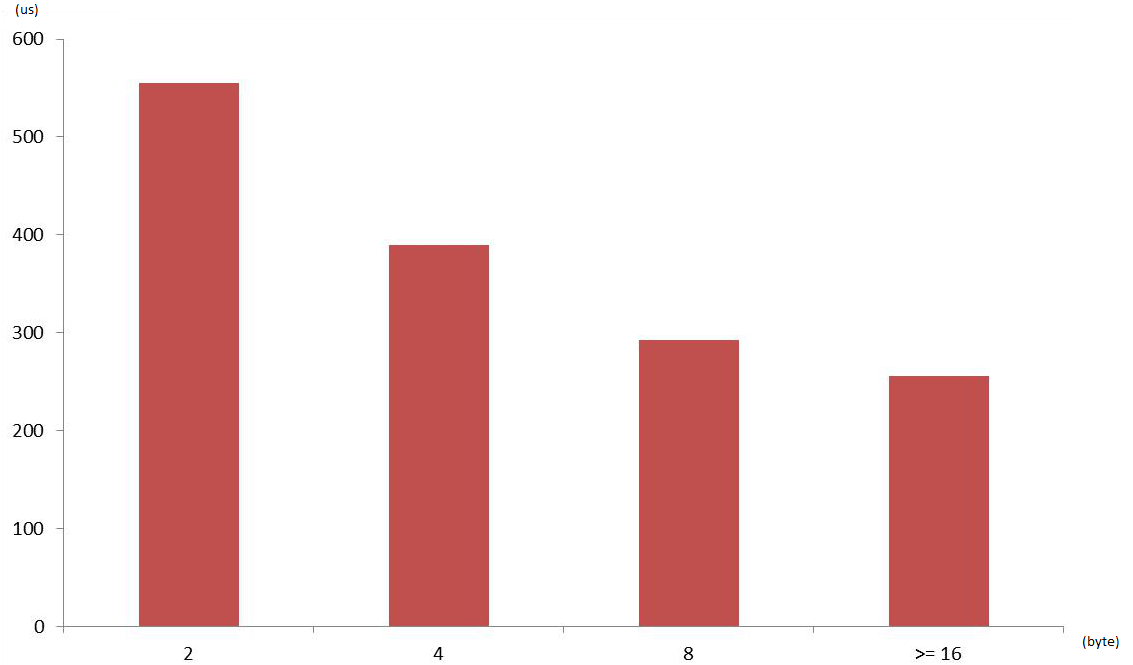
This shows that using very low memory alignment can affect the performance of our program. Nevertheless, using very restrictive memory alignment doesn’t worth because I’ve seen any serious difference between memory alignments greater than 16 bytes.
Conclusion
I’ve found that using very low memory alignment can be harmful for performance. However, I expected to see more results related with the size of the elements. Perhaps prefetching is solving this problem. Furthermore, I guess that vectorization may have something to do with these results. In any case, it should be studied in more depth.