Compiler Optimization for Energy Efficiency
16 Aug 2017Introduction
Unsurprisingly hardware architecture research is every day more focused on energy efficiency, and sometimes leaves performance in the background. New architectures like big.LITTLE are moving in that direction combined with reductions of the size of the chips. However, all these advancements are based on hardware architecture so programmers can do very little.
For that reason, I want to cover a technique to reduce energy consumption based on compiler optimization instead of relying on hardware design.
Classical Approaches
Energy efficiency is not a new topic. Voltage scaling has long been applied to reduce power consumption. It’s simply based on reducing the frequency of the processor. However, it inevitably reduces performance. That’s one of the main reasons why energy efficiency is usually associated with low performance.
It has also been tried to scale the voltage dynamically depending on CPU usage, this technique is called Dynamic Voltage Frequency Scaling (DVFS). But often idle periods are very short and doesn’t worth changing the voltage so many times just for a few cycles. That’s mainly because the processor needs a little time to change the voltage. So the ideal frequency change looks like this:

But the real the frequency change would look something like this:

The problem of the real case is that during the idle periods the frequency is not as low as it could (more power consumption) and during the high usage periods the frequency takes time to rise (less performance). For that reason the objective is to scale the voltage when the processor is going to be idle for a long time, for example when it’s loading big amounts of information from memory.
Therefore the ideal program would have long memory loading phases (memory-bound) interspersed with long high CPU usage phases (compute-bound). Based on this idea arises the following technique which aims to compile programs with the mentioned structure.
Decoupled Access-Execution
Decoupled Access-Execution (DAE) is a hardware architecture proposed by J.E. Smith in 1982. The main feature of this architecture is a high degree of decoupling between operand access and execution. However, the idea of DAE can be oriented to a software approach. We can use it as a compiler optimization technique to reorder the instructions of the code to group memory loading instructions to create long memory-bound and compute-bound phases. This way DVFS can be applied effectively.
Let’s consider an example. Very often we access an element of an array and then we perform some operations with it.
for (int i = 0; i < N; ++i) {
x = A[i];
/*Operations with X*/
}In this classical example loading an element doesn’t require much CPU usage. However, scaling the voltage for just one element doesn’t worth. If we represent the ideal CPU usage of this code it would look something like this:

Nevertheless a compiler could propose the following change:
for (int i = 0; i < N; ++i) {
prefetch A[i];
}
for (int i = 0; i < N; ++i) {
x = load A[i];
/*Operations with X*/
}Obtaining an almost ideal organization of the CPU usage, something almost like this:
As you can see the idea of this technique is quite simple. In the Access phase we prefetch data to the L1 cache and in the Execution phase we use that data. Furthermore by grouping data loading we can take advantage of memory-level parallelism.
Notice that although this example might look too simple and can be done by hand, the advantage of relying on compilers is that we can use advanced optimization techniques to apply reordering to codes whose access patterns look too complex for humans. In addition, developers avoid changing their code, which is something that involves many drawbacks.
Benchmarks
Although this technique is at early stages, a few benchmarks have already been done using DVFS with DAE and without it. Most of them are the classical synthetic benchmarks like Cholesky or FFT.
The first one compares the power consumption (normalized):
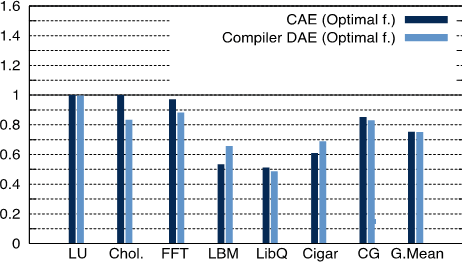
And the second one the performance (normalized):
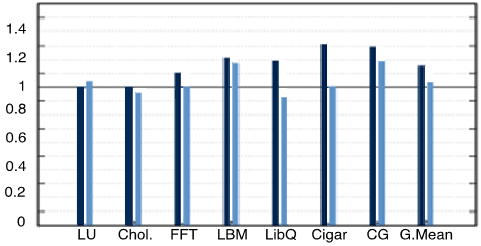
The first thing you can notice is that the results depend a lot on the program. Therefore there are programs where DAE doesn’t affect them at all. Secondly, although using DVFS without DAE improves energy efficiency it inevitably reduces performance; drawback that is reduced with DAE.
However these are synthetic benchmarks, so although they are relevant they should not be considered as a proof of the quality of this technique.
Drawbacks
Obviously DAE is not perfect and although I don’t know it thoroughly, I’ve thought about a few problems that it might have.
Cache Size
The main idea of this approach is prefetching data to L1 cache. But it’s well known that L1 cache is very small so the amount of data that we can prefetch is limited by its size. Therefore, the memory-bound phased won’t be as long as we would like.
An approach to fix this limitation would be to consider prefetching to L2 and L3 cache. However, this would have effects on performance, because loading data from these cache levels takes way longer than loading from L1. Thus this option would be interesting when it’s crucial to reduce power consumption.
Search
Another important limitation is how it can be applied when searching in data structures. For example, if we are looking for an element in an array, doesn’t worth loading the full array if the element that we are looking for is at the first position. Or when we are doing a binary search and we need to know the value of the element loaded before choosing which element will be loaded.
The current approach of this technique is to duplicate the code in these cases so it produces an increment of the size of the binaries. However, there are new approaches to reorder instructions instead of duplicating them like Clairvoyance.
Architecture
Finally, notice that this technique is very architecture dependent. On the one hand it relies on the capacity of the processor to use DVFS. And on the other hand the processor may already being doing some scheduling or changing cores instead of scaling voltage. For that reason I guess that results will vary a lot depending on the target architecture.
Current Research
You can take a look at the paper that this article is based on to find the details. In addition, this is the repository of an open source project to apply some of these ideas to LLVM.
I would like to thank Dr. Alexandra Jimborean for introducing me this technique in an invited talk at University of Murcia.
Conclusion
It’s well known that energy efficiency is a crucial issue. However, it has always been almost exclusively a hardware architecture topic. But with these kinds of approach energy efficiency optimization goes a step further. Although this technique is at early stages the results are interesting so time will tell if it can be widely adopted.