16 Aug 2017
Introduction
Unsurprisingly hardware architecture research is every day more focused on energy efficiency, and sometimes leaves performance in the background. New architectures like big.LITTLE are moving in that direction combined with reductions of the size of the chips. However, all these advancements are based on hardware architecture so programmers can do very little.
For that reason, I want to cover a technique to reduce energy consumption based on compiler optimization instead of relying on hardware design.
Classical Approaches
Energy efficiency is not a new topic. Voltage scaling has long been applied to reduce power consumption. It’s simply based on reducing the frequency of the processor. However, it inevitably reduces performance. That’s one of the main reasons why energy efficiency is usually associated with low performance.
It has also been tried to scale the voltage dynamically depending on CPU usage, this technique is called Dynamic Voltage Frequency Scaling (DVFS). But often idle periods are very short and doesn’t worth changing the voltage so many times just for a few cycles. That’s mainly because the processor needs a little time to change the voltage.
So the ideal frequency change looks like this:

But the real the frequency change would look something like this:

The problem of the real case is that during the idle periods the frequency is not as low as it could (more power consumption) and during the high usage periods the frequency takes time to rise (less performance). For that reason the objective is to scale the voltage when the processor is going to be idle for a long time, for example when it’s loading big amounts of information from memory.
Therefore the ideal program would have long memory loading phases (memory-bound) interspersed with long high CPU usage phases (compute-bound). Based on this idea arises the following technique which aims to compile programs with the mentioned structure.
Read more
09 Aug 2017
Introduction
Often we try to analyze huge amounts of data to find useful information or to predict future events. One of the most important types of dataset is time series. Time series represent a series of data points indexed in time order.
There are plenty of models to analyze this kind of series; one of those is the Vector Autoregression Model.
The Vector Autoregression Model, better known as VAR, is a model for time series that has been widely used in econometrics. The main idea of this model is that the value of a variable at a time point depends linearly on the value of different variables at previous instants of time. For example the number of births in a given month might be predicted from the value of the fertile population 9 months earlier.
However, these kinds of model have an important computational cost. Fortunately, as in many other methods of machine learning now we have the required computing capacity to apply them to huge datasets. Furthermore, we can apply it not only to econometrics but also to different fields like health or weather, or simply to any problem which works with time series.
In this article I will explain the fundamentals of VAR, how to build and evaluate this model, an approach to find VAR models from a given data and parameters; and a proposal to take this method further using a guided search to find the best configuration for the model.
Read more
11 Jul 2017
Introduction
Memory alignment is not a hot topic. Usually, we don’t worry about it and very few people will bother to know if the pointer returned by malloc is 16 or 64 bytes aligned. However, I suspect that memory alignment may affect the performance someway in x86-64 processors.
In this article I want to analyze if memory alignment has effects on performance.
Previous Work
Although this has been partially studied I’ll try to fill some gaps. On the one hand, Lemire D. covered the performance when iterating all the elements of an array. However, this case is not that interesting because if you load all the elements the number of cache misses at the end will be almost the same. On the other hand Gauthier L. covered a specific access pattern which showed better performance with aligned access.
However, this approaches didn’t considered the alignment of the memory allocated but the way data is accessed.
Therefore, I will focus on analyzing if the alignment of the memory allocated affects the performance when doing random access. I won’t force the unalignment; instead I will use memory allocators that only guarantee some level of alignment.
Read more
05 Jul 2017
Introduction
The Travelling Salesman Problem (TSP) is one of those few problems that caught my attention from the first moment. Probably because is a fairly simple concept, although there is a lot of complexity in it. Let’s remember the problem statement.
Given a list of cities and the distances between each pair of cities, what is the shortest possible route that visits each city exactly once and returns to the origin city?
This statement is rather easy to understand. However, it supposes that you can always move from one city to any other, and I’ve thought many times that this is not the most interesting approach for a Travelling Salesman.
The idea of every node connected with every node sounds sometimes too ideal. In lot of problems that will not be possible. If you are visiting cities maybe you can’t go from one city to another because there is a river or no road. For example this graph which represents a road map.
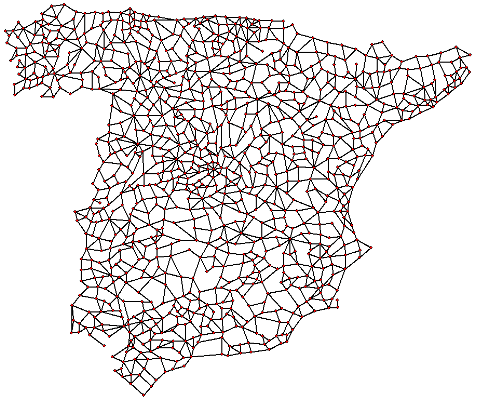
Although is not necessary being so literal to notice that working with sparse graphs instead of complete graphs might be interesting. Moreover, in this variation, we should be able to repeat nodes to ensure that we find the optimal tour.
In this article, I will explain the Sparse Travelling Salesman Problem and an interesting approach to solve it.
Read more
29 Jun 2017
Introduction
I would dare to say that linked lists and vectors are the most widely used data structures. Supposedly, we all know which one is better of each task so we can choose wisely. However, the reasoning for choosing a data structure is mostly based in the famous Big-O notation. Unfortunately, this notation doesn’t consider the details of computers so it could lead us astray.
In this article, I am going to compare the performance of linked lists against vectors when we want to store elements in order of insertion (push_back). This is one of the few cases where I consider linked lists to be a good choice. I won’t cover random insertion and elimination because there is no doubt about the poor performance of vectors in that case.
I can recommend lots of comparisons like this one comparing the performance of different data structures with respect to the number of elements. However, this doesn’t show us the reasons and the results that we are looking for. Instead, I will try to explain the aspects that can affect their performance and how to choose the best option according to these factors, avoiding easy conclusions.
Read more